

This is part one of a three part blog series on filters and filter failure. In the first of this series of posts, I reflect on the term ‘filter failure’ and analyse whether the statement ‘it’s not information overload, it’s filter failure’ still holds true. I then suggest a two-stage ‘filtration model’ for critical web literacy, built on both computer and human technology. In part two, I provide resources and ideas for creating and refining the first layer of filtration using computer technology. The third post then examines the second part of my filtration prototype, the human filtration system known as ‘the brain’. Using this two-stage filtration process, I argue that we can work to overcome filter failure; but only with persistence and effort.
(Please note, although I wrote this introduction tongue in cheek, I absolutely take the concepts of critical web literacy and digital content curation very seriously, and I hope that you find these posts both entertaining and useful).
It was waaay back in 2008 when Clay Shirky delivered the keynote at the Web 2.0 Expo in New York entitled ‘It’s not information overload: It’s filter failure‘.
Shirky reflected on how for at least fifteen years, the concept of information overload had been topical in tech journalism, and that perhaps the problem wasn’t the astronomical increase in information, rather the lack of an effective mechanism for filtering that information. He reminded us that prior to the internet, all methods of mass communication – book publishing, television, radio – had a high cost attached to production. When that cost was removed, and we entered the ‘post-Gutenberg economy’, much of the filtering for quality was also removed. With a mass communication tool that enabled very low cost production, quality was no longer one of the key determinants as to whether information received publication. This may have been good for the democratization of media (which is still debatable, but the topic of another, different post), but it resulted in a massive increase in the amount of information being communicated, in multiplying channels, every day.
The entire talk is interesting (and you can view it here), however, it is the last few minutes that really captures what I want to talk about today:
This keynote is nine years’ old, and yet I wonder if we have heard Shirky’s message?
Sifting and Sorting
In 2008, Shirky was not just looking for new tools to address the massive structural changes that the internet had wrought (and continues to create). He was challenging us to embrace a mindshift that realised information overload as normal, and to run with it – “that we are to information overload as a fish is to water”.
In some ways, we have done this – there have been massive improvements in technologies that help sift information and filter it – how many spam do you receive in your inbox compared to back in 2008? -and incredible leaps in algorithmic technology to make Google search and similar work more naturally and potentially more effectively than ever before.
However in many ways we have not. We can still feel swamped with information, and what’s more, now we aren’t even sure if the information we do access is valid and reliable.
With every positive application of filtering technology comes exploitation. The top hit on the search engine is not necessarily the one that is the most accurate, or the most useful; it is the one that has best penetrated and negotiated the various filters Google uses to bring back the hits it thinks you want. And it still thinks like a machine; we haven’t reached the singularity yet!
So on this day, nine years after Shirky’s keynote, and for every day until computers become as powerful as the human brain, and hopefully, for every day after that, I would like to suggest that we run a two-stage filtration process, with the final, and most effective filter being our brain. While prior to the internet others acted as filters; editors, publishers, ‘the media’…today we must tackle information overload ourselves.
Really?
Of course, we don’t have to do the entire job. I did say it was a two-stage filtration prototype. We can (and do) offload simpler tasks, and the ‘first round sorting’ to computers. We use our spam box and it’s ability to ‘learn’ what we mark as spam to filter marketing materials and money-making scams from much of our email. We trust Google’s algorithm and Facebook’s news feed to promote world events to our attention. Hopefully we have strategically and carefully curated online network of connections, so that they will feed forward valuable and relevant information, in a balanced way.
But we can’t place our complete faith in automated code to do our filtering. It’s just not good enough.
What is the evidence that supports this statement? Two words: fake news.
This is exhibit A in my case for arguing the importance of applying high quality, two stage filtration when dealing with information overload. While fake news pertains most specifically to political misinformation and disinformation, it serves as a powerful reminder that information on the internet does not go through an editorial process.
Fake news is a term that appears almost daily in news bulletins, and which I have written about in depth before. Some argue that fake news, filter bubbles and echo chambers are under-researched and over-hyped, and this may be true. I definitely agree that fake news is the ‘buzzword du jour‘ right now. However this research focuses specifically on those seeking political news via internet and media channels. It is possible that while many have a healthy skepticism when listening to news reports about politics and government, that critical view may relax when looking at more general information. The article also goes on to say that it is “the least politically interested people and the least skilled internet users as most susceptible to fake news, filter bubbles and echo chambers online.”
I would argue that despite their almost apparently physical connection to phones and social media, many young people fall into this category. Just like anything, critical web literacy needs to be taught, and it is for this group that I think the two-stage filtration model will be of most importance. I haven’t done the research to argue beyond anecdotal evidence, however I think we all need regular refreshing of our critical literacy skills. As a librarian and student, who is online and accessing information all of the time, I regularly have to stop and remind myself to question the source; particularly when information is presented convincingly and professionally.
But I don’t have time!
I know. You’re busy. So am I. And evaluating every piece of information for accuracy and validity is not easy! This is why we often feel overwhelmed; not just by the sheer amount of information, but also by the fact that of all of the information you do process, most of it hasn’t been vetted for quality. Even the nightly news bulletin on TV peddles so much advertising that it makes you wonder just what angle they’re pushing when they report on different events.
I don’t have a solution. I do, however have a suggestion for how to develop the best filter possible in the circumstances.
This is a two-step filter process. It uses both computer and human technology for the best results. Here’s a prototype:
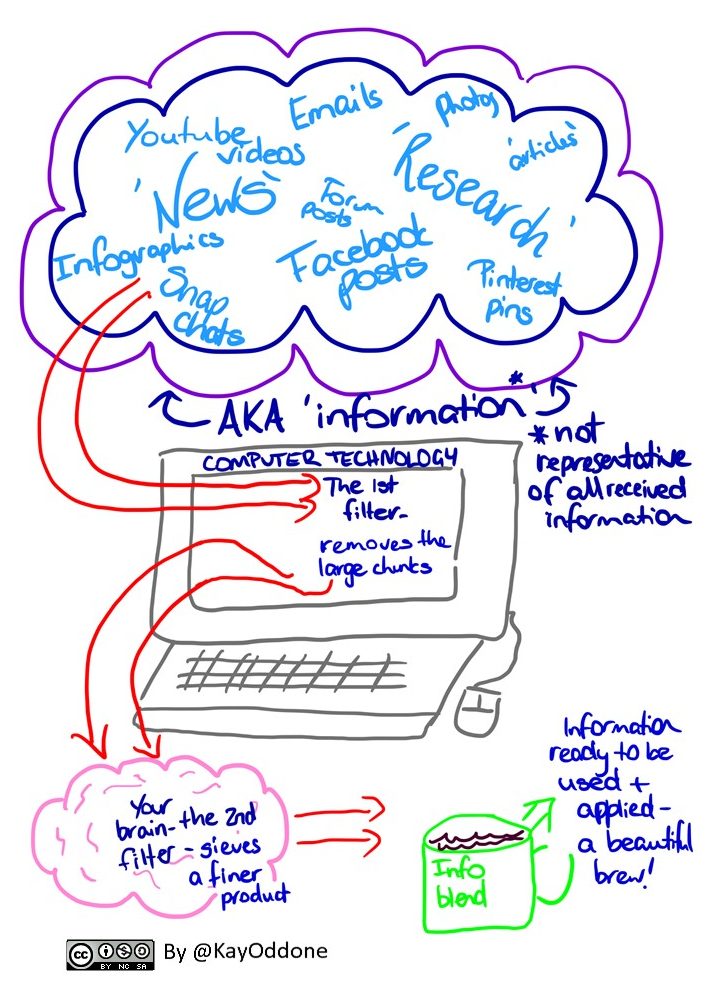
1st stage: exploit computer technology as effectively as possible as your first filter layer (using things like social media settings, digital content curation & different search techniques)
2nd stage: Enhancing your finely grained ‘brain’ filter with strong analytical and evaluative thinking strategies.
In parts two and three of this blog series, I will share resources and strategies for developing the first and second layers of this filtration system. I hope you have found this post useful, and will be interested in finding out more about how we can overcome ‘filter failure’.
If you’ve gotten to the bottom of the post, you are probably now wondering what is with the grainy image of an old car at the top of this post. The answer: not much! I went through a stage of playing with the many filters on Instagram, to the point where nothing I photographed looked as it did in real life. These filters change the way we see things; and I was thinking about how filters perform not just a refining action, but also can fundamentally change the nature of the product they are sieving. Perhaps a part four to this series is needed! What do you think? 🙂


